publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2024
-
 SmartPlay : A Benchmark for LLMs as Intelligent AgentsYue Wu, Xuan Tang, Tom M. Mitchell, and 1 more authorIn ICLR, 2024
SmartPlay : A Benchmark for LLMs as Intelligent AgentsYue Wu, Xuan Tang, Tom M. Mitchell, and 1 more authorIn ICLR, 2024Recent large language models (LLMs) have demonstrated great potential toward intelligent agents and next-gen automation, but there currently lacks a systematic benchmark for evaluating LLMs’ abilities as agents. We introduce SmartPlay: both a challenging benchmark and a methodology for evaluating LLMs as agents. SmartPlay consists of 6 different games, including Rock-Paper-Scissors, Tower of Hanoi, Minecraft. Each game features a unique setting, providing up to 20 evaluation settings and infinite environment variations. Each game in SmartPlay uniquely challenges a subset of 9 important capabilities of an intelligent LLM agent, including reasoning with object dependencies, planning ahead, spatial reasoning, learning from history, and understanding randomness. The distinction between the set of capabilities each game test allows us to analyze each capability separately. SmartPlay serves not only as a rigorous testing ground for evaluating the overall performance of LLM agents but also as a road-map for identifying gaps in current methodologies. We release our benchmark at this github.com/microsoft/SmartPlay
@inproceedings{smartplay, title = {SmartPlay : A Benchmark for LLMs as Intelligent Agents}, author = {Wu, Yue and Tang, Xuan and Mitchell, Tom M. and Li, Yuanzhi}, booktitle = {ICLR}, year = {2024}, } -
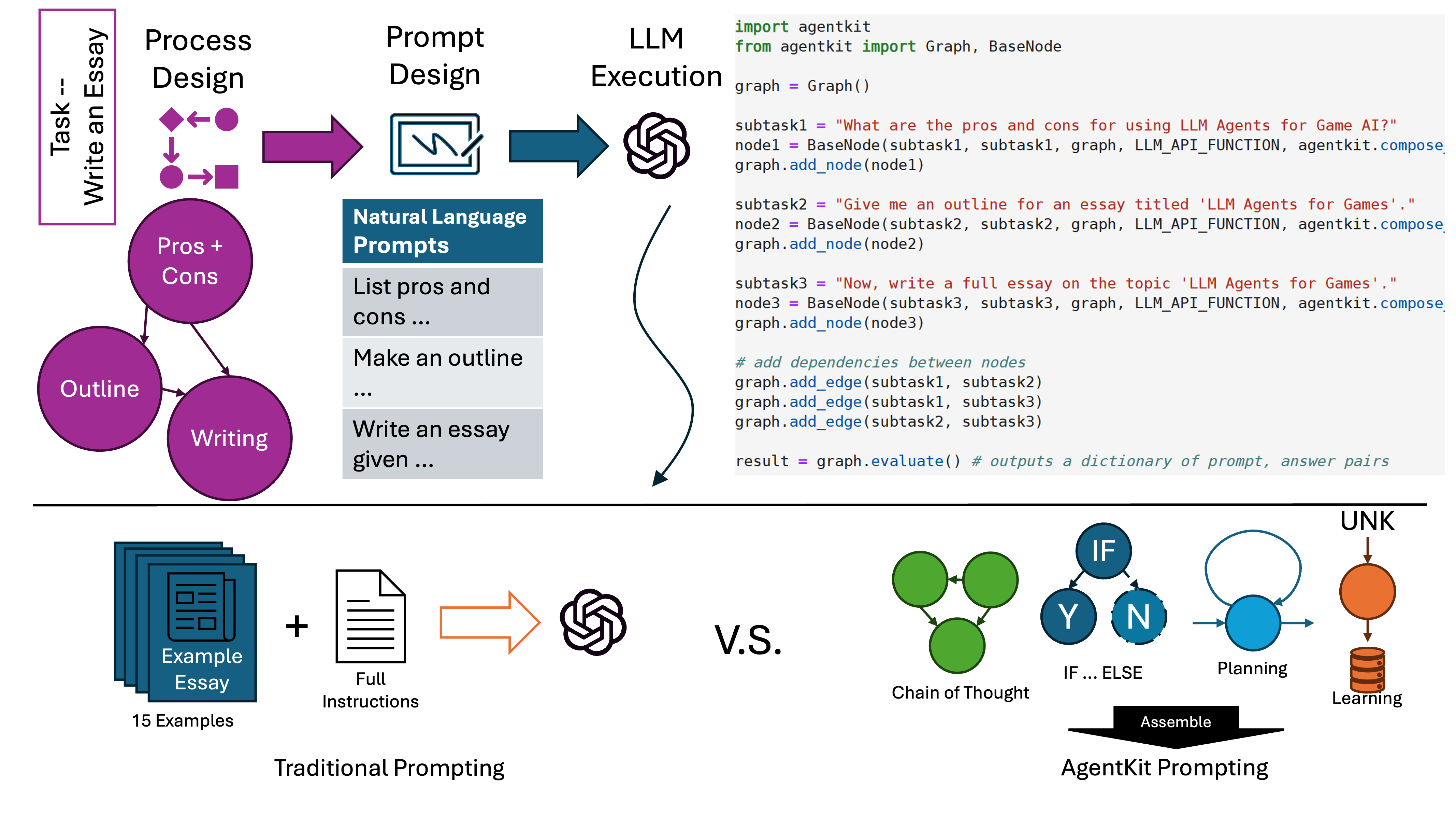 AgentKit: Flow Engineering with Graphs, not CodingYue Wu, Yewen Fan, So Yeon Min, and 6 more authorsIn COLM, 2024
AgentKit: Flow Engineering with Graphs, not CodingYue Wu, Yewen Fan, So Yeon Min, and 6 more authorsIn COLM, 2024We propose an intuitive LLM prompting framework (AgentKit) for multifunctional agents. AgentKit offers a unified framework for explicitly constructing a complex "thought process" from simple natural language prompts. The basic building block in AgentKit is a node, containing a natural language prompt for a specific subtask. The user then puts together chains of nodes, like stacking LEGO pieces. The chains of nodes can be designed to explicitly enforce a naturally structured "thought process". For example, for the task of writing a paper, one may start with the thought process of 1) identify a core message, 2) identify prior research gaps, etc. The nodes in AgentKit can be designed and combined in different ways to implement multiple advanced capabilities including on-the-fly hierarchical planning, reflection, and learning from interactions. In addition, due to the modular nature and the intuitive design to simulate explicit human thought process, a basic agent could be implemented as simple as a list of prompts for the subtasks and therefore could be designed and tuned by someone without any programming experience. Quantitatively, we show that agents designed through AgentKit achieve SOTA performance on WebShop and Crafter. These advances underscore AgentKit’s potential in making LLM agents effective and accessible for a wider range of applications.
@inproceedings{agentkit, title = {AgentKit: Flow Engineering with Graphs, not Coding}, author = {Wu, Yue and Fan, Yewen and Min, So Yeon and Prabhumoye, Shrimai and McAleer, Stephen and Bisk, Yonatan and Salakhutdinov, Ruslan and Li, Yuanzhi and Mitchell, Tom}, year = {2024}, booktitle = {COLM}, } -
 Phi-4 Technical ReportMarah Abdin, Jyoti Aneja, Harkirat Behl, and 24 more authorsPreprint, 2024
Phi-4 Technical ReportMarah Abdin, Jyoti Aneja, Harkirat Behl, and 24 more authorsPreprint, 2024@article{abdin2024phi, title = {Phi-4 Technical Report}, author = {Abdin, Marah and Aneja, Jyoti and Behl, Harkirat and Bubeck, Sébastien and Eldan, Ronen and Gunasekar, Suriya and Harrison, Michael and Hewett, Russell J. and Javaheripi, Mojan and Kauffmann, Piero and Lee, James R. and Lee, Yin Tat and Li, Yuanzhi and Liu, Weishung and Mendes, Caio C. T. and Nguyen, Anh and Price, Eric and de Rosa, Gustavo and Saarikivi, Olli and Salim, Adil and Shah, Shital and Wang, Xin and Ward, Rachel and Wu, Yue and Yu, Dingli and Zhang, Cyril and Zhang, Yi}, journal = {Preprint}, year = {2024} }



2023
-
 Read and Reap the Rewards: Learning to Play Atari with the Help of Instruction ManualsYue Wu, Yewen Fan, Paul Pu Liang, and 3 more authorsIn NeurIPS, 2023RRL Workshop, ICLR 2023 (oral)
Read and Reap the Rewards: Learning to Play Atari with the Help of Instruction ManualsYue Wu, Yewen Fan, Paul Pu Liang, and 3 more authorsIn NeurIPS, 2023RRL Workshop, ICLR 2023 (oral)High sample complexity has long been a challenge for RL. On the other hand, humans learn to perform tasks not only from interaction or demonstrations, but also by reading unstructured text documents, e.g., instruction manuals. Instruction manuals and wiki pages are among the most abundant data that could inform agents of valuable features and policies or task-specific environmental dynamics and reward structures. Therefore, we hypothesize that the ability to utilize human-written instruction manuals to assist learning policies for specific tasks should lead to a more efficient and better-performing agent. We propose the Read and Reward framework. Read and Reward speeds up RL algorithms on Atari games by reading manuals released by the Atari game developers. Our framework consists of a QA Extraction module that extracts and summarizes relevant information from the manual and a Reasoning module that evaluates object-agent interactions based on information from the manual. Auxiliary reward is then provided to a standard A2C RL agent, when interaction is detected. When assisted by our design, A2C improves on 4 games in the Atari environment with sparse rewards, and requires 1000x less training frames compared to the previous SOTA Agent 57 on Skiing, the hardest game in Atari.
@inproceedings{wu2023read, title = {Read and Reap the Rewards: Learning to Play Atari with the Help of Instruction Manuals}, author = {Wu, Yue and Fan, Yewen and Liang, Paul Pu and Azaria, Amos and Li, Yuanzhi and Mitchell, Tom M}, booktitle = {NeurIPS}, year = {2023}, } - Graph Generative Model for Benchmarking Graph Neural NetworksMinji Yoon, Yue Wu, John Palowitch, and 2 more authorsIn ICML, 2023
As the field of Graph Neural Networks (GNN) continues to grow, it experiences a corresponding increase in the need for large, real-world datasets to train and test new GNN models on challenging, realistic problems. Unfortunately, such graph datasets are often generated from online, highly privacy-restricted ecosystems, which makes research and development on these datasets hard, if not impossible. This greatly reduces the amount of benchmark graphs available to researchers, causing the field to rely only on a handful of publicly-available datasets. To address this problem, we introduce a novel graph generative model, Computation Graph Transformer (CGT) that learns and reproduces the distribution of real-world graphs in a privacy-controlled way. More specifically, CGT (1) generates effective benchmark graphs on which GNNs show similar task performance as on the source graphs, (2) scales to process large-scale graphs, (3) incorporates off-the-shelf privacy modules to guarantee end-user privacy of the generated graph. Extensive experiments across a vast body of graph generative models show that only our model can successfully generate privacy-controlled, synthetic substitutes of large-scale real-world graphs that can be effectively used to benchmark GNN models.
@inproceedings{yoon2023graph, title = {Graph Generative Model for Benchmarking Graph Neural Networks}, author = {Yoon, Minji and Wu, Yue and Palowitch, John and Perozzi, Bryan and Salakhutdinov, Ruslan}, year = {2023}, booktitle = {ICML}, } - Plan, Eliminate, and Track–Language Models are Good Teachers for Embodied AgentsYue Wu, So Yeon Min, Yonatan Bisk, and 5 more authorsPreprint, 2023
Pre-trained large language models (LLMs) capture procedural knowledge about the world. Recent work has leveraged LLM’s ability to generate abstract plans to simplify challenging control tasks, either by action scoring, or action modeling (fine-tuning). However, the transformer architecture inherits several constraints that make it difficult for the LLM to directly serve as the agent: e.g. limited input lengths, fine-tuning inefficiency, bias from pre-training, and incompatibility with non-text environments. To maintain compatibility with a low-level trainable actor, we propose to instead use the knowledge in LLMs to simplify the control problem, rather than solving it. We propose the Plan, Eliminate, and Track (PET) framework. The Plan module translates a task description into a list of high-level sub-tasks. The Eliminate module masks out irrelevant objects and receptacles from the observation for the current sub-task. Finally, the Track module determines whether the agent has accomplished each sub-task. On the AlfWorld instruction following benchmark, the PET framework leads to a significant 15% improvement over SOTA for generalization to human goal specifications.
@article{PET, title = {Plan, Eliminate, and Track--Language Models are Good Teachers for Embodied Agents}, author = {Wu, Yue and Min, So Yeon and Bisk, Yonatan and Salakhutdinov, Ruslan and Azaria, Amos and Li, Yuanzhi and Mitchell, Tom and Prabhumoye, Shrimai}, journal = {Preprint}, year = {2023}, } -
 SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and ReasoningYue Wu, So Yeon Min, Shrimai Prabhumoye, and 5 more authorsIn NeurIPS, 2023
SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and ReasoningYue Wu, So Yeon Min, Shrimai Prabhumoye, and 5 more authorsIn NeurIPS, 2023Open-world survival games pose significant challenges for AI algorithms due to their multi-tasking, deep exploration, and goal prioritization requirements. Despite reinforcement learning (RL) being popular for solving games, its high sample complexity limits its effectiveness in complex open-world games like Crafter or Minecraft. We propose a novel approach, SPRING, to read the game’s original academic paper and use the knowledge learned to reason and play the game through a large language model (LLM). Prompted with the LaTeX source as game context and a description of the agent’s current observation, our SPRING framework employs a directed acyclic graph (DAG) with game-related questions as nodes and dependencies as edges. We identify the optimal action to take in the environment by traversing the DAG and calculating LLM responses for each node in topological order, with the LLM’s answer to final node directly translating to environment actions. In our experiments, we study the quality of in-context "reasoning" induced by different forms of prompts under the setting of the Crafter open-world environment. Our experiments suggest that LLMs, when prompted with consistent chain-of-thought, have great potential in completing sophisticated high-level trajectories. Quantitatively, SPRING with GPT-4 outperforms all state-of-the-art RL baselines, trained for 1M steps, without any training. Finally, we show the potential of games as a test bed for LLMs.
@inproceedings{wu2023spring, title = {SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning}, author = {Wu, Yue and Min, So Yeon and Prabhumoye, Shrimai and Bisk, Yonatan and Salakhutdinov, Ruslan and Azaria, Amos and Mitchell, Tom and Li, Yuanzhi}, booktitle = {NeurIPS}, year = {2023}, } - HELPER: Instructable and Personalizable Embodied Agents with Memory-Augmented Context-Dependent LLM PromptingIn EMNLP Findings, 2023

2022
-
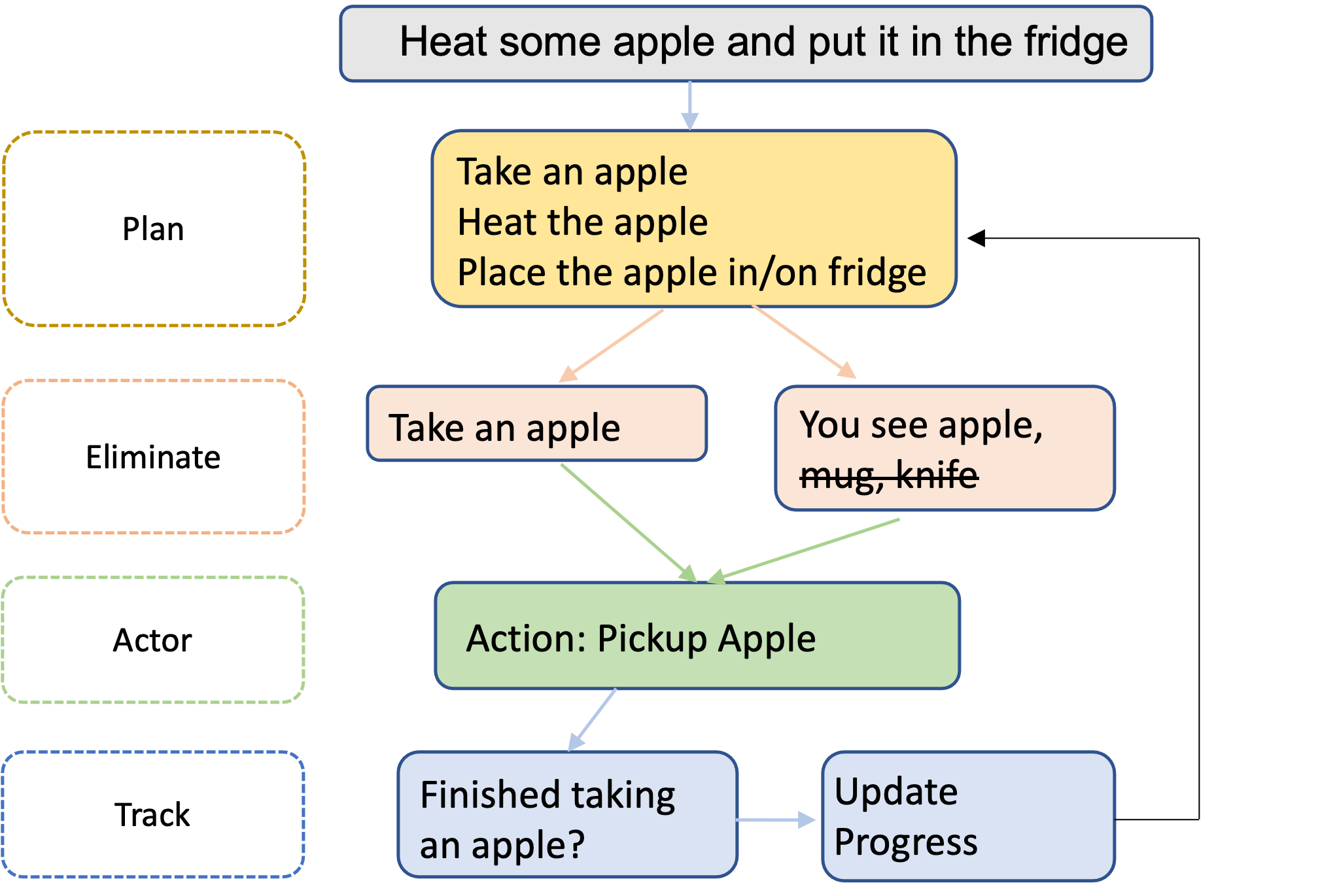 Tackling AlfWorld with Action Attention and Common Sense from Language ModelsYue Wu, So Yeon Min, Yonatan Bisk, and 2 more authorsIn Workshop on Language and Reinforcement Learning, NeurIPS, 2022
Tackling AlfWorld with Action Attention and Common Sense from Language ModelsYue Wu, So Yeon Min, Yonatan Bisk, and 2 more authorsIn Workshop on Language and Reinforcement Learning, NeurIPS, 2022Pre-trained language models (LMs) capture strong prior knowledge about the world. This common sense knowledge can be used in control tasks. However, directly generating actions from LMs may result in a reasonable narrative, but not executable by a low level agent. We propose to instead use the knowledge in LMs to simplify the control problem, and assist the low-level actor training. We implement a novel question answering framework to simplify observations and an agent that handles arbitrary roll-out length and action space size based on action attention. On the Alfworld benchmark for indoor instruction following, we achieve a significantly higher success rate (50% over the baseline) with our novel object masking - action attention method.
@inproceedings{wutackling, title = {Tackling AlfWorld with Action Attention and Common Sense from Language Models}, author = {Wu, Yue and Min, So Yeon and Bisk, Yonatan and Salakhutdinov, Ruslan and Prabhumoye, Shrimai}, booktitle = {Workshop on Language and Reinforcement Learning, NeurIPS}, year = {2022}, }

2021
- Self-supervised Learning from a Multi-view PerspectiveYao-Hung Hubert Tsai, Yue Wu, Ruslan Salakhutdinov, and 1 more authorIn ICLR, 2021
As a subset of unsupervised representation learning, self-supervised representation learning adopts self-defined signals as supervision and uses the learned representation for downstream tasks, such as object detection and image captioning. Many proposed approaches for self-supervised learning follow naturally a multi-view perspective, where the input (e.g., original images) and the self-supervised signals (e.g., augmented images) can be seen as two redundant views of the data. Building from this multi-view perspective, this paper provides an information-theoretical framework to better understand the properties that encourage successful self-supervised learning. Specifically, we demonstrate that self-supervised learned representations can extract task-relevant information and discard task-irrelevant information. Our theoretical framework paves the way to a larger space of self-supervised learning objective design. In particular, we propose a composite objective that bridges the gap between prior contrastive and predictive learning objectives, and introduce an additional objective term to discard task-irrelevant information. To verify our analysis, we conduct controlled experiments to evaluate the impact of the composite objectives. We also explore our framework’s empirical generalization beyond the multi-view perspective, where the cross-view redundancy may not be clearly observed.
@inproceedings{tsaiself, title = {Self-supervised Learning from a Multi-view Perspective}, author = {Tsai, Yao-Hung Hubert and Wu, Yue and Salakhutdinov, Ruslan and Morency, Louis-Philippe}, booktitle = {ICLR}, year = {2021}, } -
 Uncertainty Weighted Actor-Critic for Offline Reinforcement LearningYue Wu, Shuangfei Zhai, Nitish Srivastava, and 4 more authorsIn ICML, 2021
Uncertainty Weighted Actor-Critic for Offline Reinforcement LearningYue Wu, Shuangfei Zhai, Nitish Srivastava, and 4 more authorsIn ICML, 2021Offline Reinforcement Learning promises to learn effective policies from previously-collected, static datasets without the need for exploration. However, existing Q-learning and actor-critic based off-policy RL algorithms fail when bootstrapping from out-of-distribution (OOD) actions or states. We hypothesize that a key missing ingredient from the existing methods is a proper treatment of uncertainty in the offline setting. We propose Uncertainty Weighted Actor-Critic (UWAC), an algorithm that models the epistemic uncertainty to detect OOD state-action pairs and down-weights their contribution in the training objectives accordingly. Implementation-wise, we adopt a practical and effective dropout-based uncertainty estimation method that introduces very little overhead over existing RL algorithms. Empirically, we observe that UWAC substantially improves model stability during training. In addition, UWAC out-performs existing offline RL methods on a variety of competitive tasks, and achieves significant performance gains over the state-of-the-art baseline on datasets with sparse demonstrations collected from human experts.
@inproceedings{wu2021uncertainty, title = {Uncertainty Weighted Actor-Critic for Offline Reinforcement Learning}, author = {Wu, Yue and Zhai, Shuangfei and Srivastava, Nitish and Susskind, Joshua M and Zhang, Jian and Salakhutdinov, Ruslan and Goh, Hanlin}, booktitle = {ICML}, pages = {11319--11328}, year = {2021}, organization = {PMLR}, }

2020
-
 Improving gan training with probability ratio clipping and sample reweightingYue Wu, Pan Zhou, Andrew G Wilson, and 2 more authorsIn NeurIPS, 2020
Improving gan training with probability ratio clipping and sample reweightingYue Wu, Pan Zhou, Andrew G Wilson, and 2 more authorsIn NeurIPS, 2020Despite success on a wide range of problems related to vision, generative adversarial networks (GANs) often suffer from inferior performance due to unstable training, especially for text generation. To solve this issue, we propose a new variational GAN training framework which enjoys superior training stability. Our approach is inspired by a connection of GANs and reinforcement learning under a variational perspective. The connection leads to (1) probability ratio clipping that regularizes generator training to prevent excessively large updates, and (2) a sample re-weighting mechanism that improves discriminator training by downplaying bad-quality fake samples. Moreover, our variational GAN framework can provably overcome the training issue in many GANs that an optimal discriminator cannot provide any informative gradient to training generator. By plugging the training approach in diverse state-of-the-art GAN architectures, we obtain significantly improved performance over a range of tasks, including text generation, text style transfer, and image generation.
@inproceedings{wu2020improving, title = {Improving gan training with probability ratio clipping and sample reweighting}, author = {Wu, Yue and Zhou, Pan and Wilson, Andrew G and Xing, Eric and Hu, Zhiting}, booktitle = {NeurIPS}, volume = {33}, pages = {5729--5740}, year = {2020}, } -
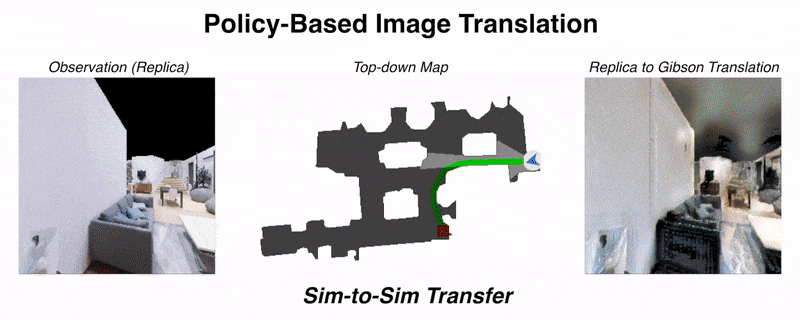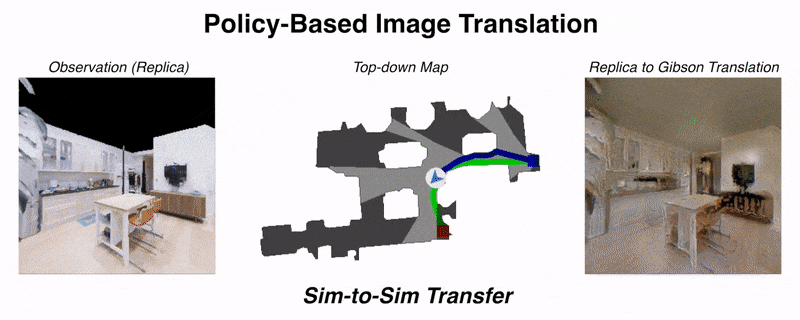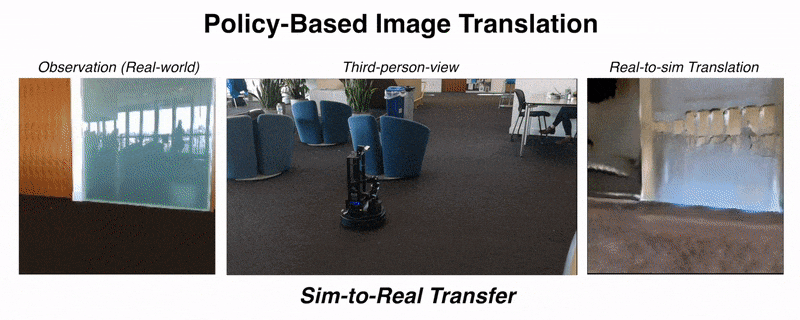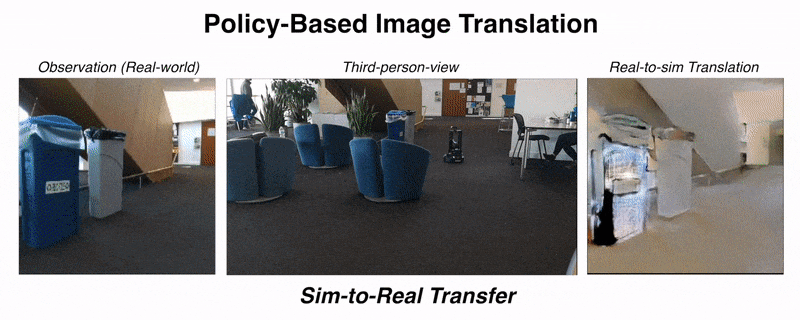 Unsupervised domain adaptation for visual navigationShangda Li, Devendra Singh Chaplot, Yao-Hung Hubert Tsai, and 3 more authorsDeep Reinforcement Learning Workshop, NeurIPS, 2020
Unsupervised domain adaptation for visual navigationShangda Li, Devendra Singh Chaplot, Yao-Hung Hubert Tsai, and 3 more authorsDeep Reinforcement Learning Workshop, NeurIPS, 2020Advances in visual navigation methods have led to intelligent embodied navigation agents capable of learning meaningful representations from raw RGB images and perform a wide variety of tasks involving structural and semantic reasoning. However, most learning-based navigation policies are trained and tested in simulation environments. In order for these policies to be practically useful, they need to be transferred to the real-world. In this paper, we propose an unsupervised domain adaptation method for visual navigation. Our method translates the images in the target domain to the source domain such that the translation is consistent with the representations learned by the navigation policy. The proposed method outperforms several baselines across two different navigation tasks in simulation. We further show that our method can be used to transfer the navigation policies learned in simulation to the real world.
@article{li2020unsupervised, title = {Unsupervised domain adaptation for visual navigation}, author = {Li, Shangda and Chaplot, Devendra Singh and Tsai, Yao-Hung Hubert and Wu, Yue and Morency, Louis-Philippe and Salakhutdinov, Ruslan}, journal = {Deep Reinforcement Learning Workshop, NeurIPS}, year = {2020}, }

2019
-
 Distributed reinforcement learning for multi-robot decentralized collective constructionGuillaume Sartoretti, Yue Wu, William Paivine, and 3 more authorsIn DARS, 2019
Distributed reinforcement learning for multi-robot decentralized collective constructionGuillaume Sartoretti, Yue Wu, William Paivine, and 3 more authorsIn DARS, 2019Inspired by recent advances in single agent reinforcement learning, this paper extends the single-agent asynchronous advantage actor-critic (A3C) algorithm to enable multiple agents to learn a homogeneous, distributed policy, where agents work together toward a common goal without explicitly interacting. Our approach relies on centralized policy and critic learning, but decentralized policy execution, in a fully-observable system. We show that the sum of experience of all agents can be leveraged to quickly train a collaborative policy that naturally scales to smaller and larger swarms. We demonstrate the applicability of our method on a multi-robot construction problem, where agents need to arrange simple block elements to build a user-specified structure. We present simulation results where swarms of various sizes successfully construct different test structures without the need for additional training.
@inproceedings{sartoretti2019distributed, title = {Distributed reinforcement learning for multi-robot decentralized collective construction}, author = {Sartoretti, Guillaume and Wu, Yue and Paivine, William and Kumar, TK Satish and Koenig, Sven and Choset, Howie}, booktitle = {DARS}, pages = {35--49}, year = {2019}, organization = {Springer}, } - Distributed learning of decentralized control policies for articulated mobile robotsGuillaume Sartoretti, William Paivine, Yunfei Shi, and 2 more authorsIEEE Transactions on Robotics, 2019
@article{sartoretti2019distributee, title = {Distributed learning of decentralized control policies for articulated mobile robots}, author = {Sartoretti, Guillaume and Paivine, William and Shi, Yunfei and Wu, Yue and Choset, Howie}, journal = {IEEE Transactions on Robotics}, volume = {35}, number = {5}, pages = {1109--1122}, year = {2019}, publisher = {IEEE} }
2017
- License plate recognition using deep FCNYue Wu, and Jianmin LiIn ICCSIP, 2017
@inproceedings{wu2017license, title = {License plate recognition using deep FCN}, author = {Wu, Yue and Li, Jianmin}, booktitle = {ICCSIP}, pages = {225--234}, year = {2017}, organization = {Springer} }